

Le modèle d'objet de document est un élément fondamental du Web. DOM en bref, il s'agit d'un ensemble de normes d'API qui définissent comment un navigateur doit construire un document Web et comment les développeurs peuvent manipuler des objets.
Nous examinerons un peu plus en détail comment fonctionne le DOM. Le modèle existe depuis des années et se situe actuellement au niveau 3 de DOM (documentation DOM3 ici). Un DOM4 est actuellement en cours de rédaction avec de nouvelles spécifications à venir. Pour l'instant, nous pouvons nous concentrer sur une brève compréhension de la création du modèle d'objet.
Une leçon d'histoire
Au début du script Web, il n'existait aucun moyen standard d'accéder aux objets de page. Cela a permis aux principaux navigateurs de créer leurs propres normes et règles de manipulation de documents. Les éditeurs de logiciels ont même écrit leurs propres langages de script tels que VBScript de Microsoft et Applescript d’Apple.
Les premiers modèles étaient très limités. Vous pouvez uniquement accéder à des éléments spécifiques tels que des images ou des entrées de formulaire. Au fil du temps, le World Wide Web Consortium a élaboré un modèle standard suivi par la plupart des principaux éditeurs de logiciels. Notamment Internet Explorer de Microsoft, Netscape, Safari et Opera.
Actuellement, le DOM a subi de nombreuses révisions et permet une manipulation très précise des éléments de page. Avec des bibliothèques de scripts telles que jQuery et MooTools Les développeurs sont en mesure de passer beaucoup moins de temps en attente de bugs.
Les scripts DOM modernes aujourd'hui
JavaScript est de loin le langage le plus populaire parmi les développeurs. Netscape a été lancé à l'origine en tant que projet open source en 1995. Il est basé sur le langage de programmation populaire Java et a été modifié par d'innombrables communautés de développeurs Web.
Le DOM lui-même n'est utile que dans les situations où il est possible d'accéder aux objets. Aujourd'hui, tous les navigateurs conformes aux normes prennent en charge tous les éléments et méthodes de manipulation DOM. Avec cette standardisation du modèle objet, nous avons assisté à une montée en puissance des scripts simples et des fonctionnalités de page.
L'arbre de document
En envisageant le DOM, il peut être facilement compris par rapport à un arbre. Lorsqu'un document est chargé, chaque élément de la page est conservé en mémoire en tant que nouvel objet. Celles-ci sont parfois appelées noeuds de l'arbre.
Par exemple, chaque page HTML appropriée doit commencer par un élément HTML et tout le contenu de la page doit se charger dans un fichier. corps élément. Cela signifie que votre hiérarchie d'arborescence commence au niveau d'un élément HTML racine et traverse son premier nœud. corps.
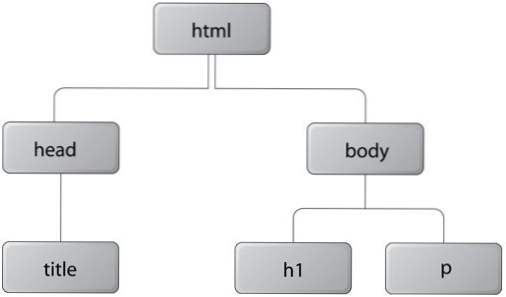
C'est une idée simple, mais elle fournit un pouvoir immense aux développeurs. À partir de cela, nous pouvons extraire de nombreux types d'éléments de la page en accédant simplement à leur nœud ou à leur emplacement spécifique dans le document. Un petit script peut être écrit pour extraire toutes les images d'une page et les placer dans un tableau afin de les stocker.
À partir de là, il est possible d'accéder à chaque élément d'image via JavaScript. Ci-dessous, j'ai ajouté du code qui définit 2 variables. Le premier contient le 3ème objet image en mémoire, le second tire le src chaîne de l'élément.
Méthodes de nœud
Une fois que vous avez la possibilité de manipuler et d'accéder aux nœuds, vous pouvez leur appliquer des fonctions. Le modèle d'objet ne sert pas uniquement à parcourir la page, mais également à appliquer de nouveaux effets.
Ceux-ci s'appellent les méthodes et ils sont écrits dans la spécification DOM. Lorsque vous imaginez un système d'arborescence basé sur des nœuds, ces méthodes dissiperont toute confusion. Vous trouverez ci-dessous un petit exemple des méthodes les plus courantes que vous pouvez utiliser sur les nœuds:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
La plupart de ces méthodes peuvent être utilisées dans une déclaration de variable ou une instruction de retour de fonction. Ils renverront un objet du DOM par rapport à votre emplacement actuel.
Les deux premiers saisiront respectivement le premier noeud interne et le dernier noeud interne. C'est ce que le mot clé enfant est censé représenter, avec noeudA être le parent des deux enfants. Cela devrait aussi expliquer comment parentNode fonctionne comme vous pouvez tirer sur l’objet noeud qui se trouve directement au-dessus de votre sélecteur actuel.

Les deux fonctions sœurs sont inconnues de la plupart des éléments cibles et se trouvent au même niveau hiérarchique. Par exemple, si vous parcouriez une liste non ordonnée avec 3 li tags que vous ne pouviez appeler nextSibling 2 fois avant de revenir nul. Depuis, beaucoup de ces fonctions ont été réduites par des bibliothèques tierces en méthodes plus rapides et plus précises.
Classes d'éléments et ID
Le ciblage direct est l’un des moyens les plus populaires de récupérer des informations sur les objets. Si vous avez écrit du code HTML, vous devez connaître les attributs de classe et d’ID. Ceux-ci peuvent être définis sur n'importe quel élément de page et sont notoirement utiles pour appliquer des styles CSS.

Lorsque vous créez ces attributs, le DOM les reconnaît en tant qu’environnements distincts du document global. Les identifiants doivent être uniques parmi votre page et provoqueront des erreurs de script si vous dupliquez le même nom. Les classes peuvent contenir d'innombrables éléments, bien qu'elles puissent s'enliser rapidement.
La méthode populaire getElementById () a été utilisé par les développeurs pendant une décennie pour simplifier le processus de manipulation d’objets. Cette méthode prend un argument de chaîne unique qui contient la valeur ID de tout élément que vous souhaitez cibler. En tant que tel, vous pouvez changer l'image src attribuer rapidement avec un code similaire:
Avancées dans le modèle
Avec la sortie de la célèbre bibliothèque jQuery, il est plus facile que jamais de développer des scripts puissants. Fonctions plus anciennes telles que getElementById () et getElementsByTagName () sont toujours accessibles, bien que déconseillé par la plupart des normes.
Le moyen le plus rapide de commencer à manipuler le DOM consiste à accéder aux objets via jQuery. Un appel de méthode simple $ (document) .ready ({}) est tout ce qui est nécessaire pour exécuter un nouvel événement. le $() La syntaxe est utilisée pour représenter l'extraction de tout type d'objet de la page.

Cela peut être utilisé à l'unisson pour extraire les identifiants et les tags d'une page. Chacun requiert simplement les mêmes symboles que ceux utilisés dans les déclarations CSS, tels que $ ('# myid') et $ ('. myclass'). Une fois à l'intérieur de la fonction ready, jQuery vous permet d'extraire autant d'événements et de fonctions que vous le souhaitez.
La bibliothèque est optimisée pour la vitesse et avec le DOM qui avance actuellement rapidement, nous assistons à des sauts considérables dans la prise en charge des scripts. Chaque nœud est chargé dans un emplacement de mémoire d’objet que le navigateur Web et développeur peut accéder.
Conclusion
Le mouvement open source a également largement contribué à l'avancement des spécifications DOM. Au cours des 10 dernières années, XML a été accueilli favorablement dans la documentation, avec différentes manières de définir les flux de contenu (RSS, Atom, etc.).
Il est important de rester au courant des tendances en tant que développeur Web. Le Web progresse rapidement et les dernières révisions du modèle d’objet document montrent le degré de contrôle disponible aujourd’hui. Si vous souhaitez approfondir vos connaissances en matière de scripts DOM, nous proposons une collection de trucs jQuery et de nombreux tutoriels vidéo de conception de sites Web entièrement gratuits!